



How to add tests to legacy code so you can understand it quickly and start making changes with confidence
18 May 2015
Taking over legacy code can be challenging. There are a whole load of issues to deal with, ranging from understanding what on earth it's supposed to be doing, to fixing massive problems with the underlying architecture. So where to start and how can you make your life easier?
What I've learned after being in this position many times is that the most important thing to do right from the start is to work on the tests. Doing this helps for several reasons, and not just the obvious ones. Normally, we look at tests as a way to be sure that the system does what it is supposed to do, and continues to do so after we add features or refactor. But there are other benefits. If you have no idea what the code you are looking at is supposed to be doing in the first place, then tests can provide you with a valuable living documentation of what is expected of it. They may not be very good (or even exist at all), but this is the best place to start.
The process of adding, understanding or improving the tests is the best way I know of to get intimately familiar with a piece of code. Far more so than just reading the implementation as it stands. What if there are odd edge cases which are completely non-obvious when looking at the code, but which the tests make clear? What are the assumptions about what sort of data is going to be coming in to the system from outside? Why have things been put together in this way - are there certain contexts and use cases, which give us clues about likely reasons for future changes? What if the main class is a 4000 line lumpen mess and you don't know what half of it does? Whatever the question, understanding and improving the test suite will help.
This post shows how I did this with a recent project and provides some pointers to techniques that I found useful.
Making resque-scheduler-web (the example I'll be using)
As I outlined here, I recently extracted some code from Resque scheduler into a separate gem and converted it from a Sinatra interface to being a Rails engine.
The gem in question provides two extra tabs in Resque Web, so you can see what Resque Scheduler is up to. I thought this looked pretty straight forwards, but it soon turned out that there were a load of actions I didn't realise were there, which did stuff I didn't understand and then redirected somewhere else. I then found a load of other pages which didn't seem to appear in the navigation and could only be reached by clicking on links in the page content, so it was more complex than I expected.
Transferring the code into a Rails Engine meany rewriting the whole test suite, as the
original Test:Unit code was incompatible with Rails 4. I settled on Rspec for the new suite,
but had the daunting task of trying to work out how best to do this and how far to go.
Based on what I learned, here's
what I recommend you do if you find yourself in a similar situation:
Step 1: Assess what tests are there using a coverage checker
This is important. If code is not covered by any tests, then don't touch it! You've no idea what you could break. There are a few ways to do this
Simplcov on the command line
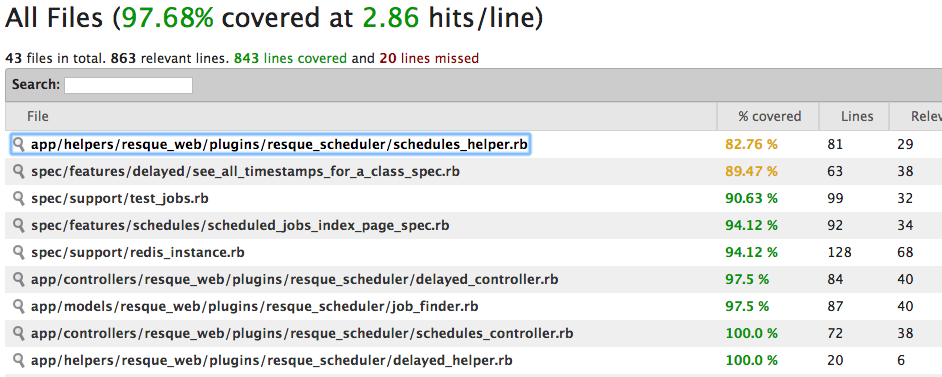
Simplecov is a gem which creates a HTML
coverage report in the /coverage directory of your
project, which you can then open in the browser. It provides and overview of all the files, then
a line-by-line breakdown of what is covered and what is not.
IDE coverage checker
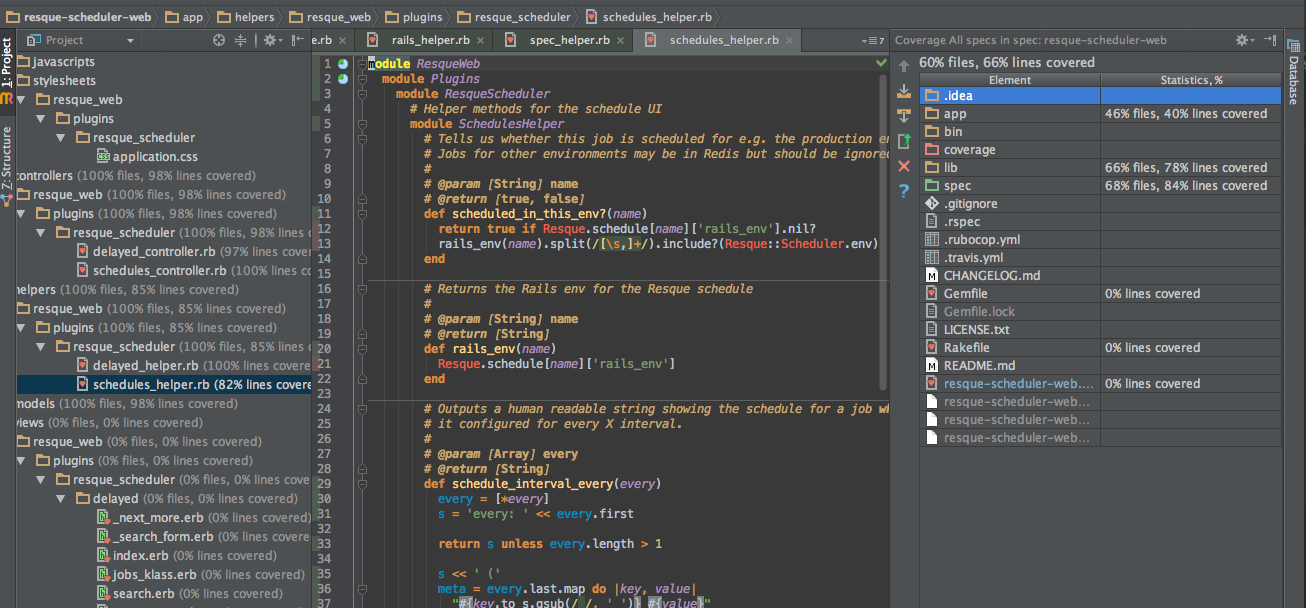
If you're an IDE fan like me (I love Rubymine - with the Vim plugin of course), then you have the option of simply running the tests with the built-on coverage checker and seeing the output right there in front of you, with a subtle coverage indicator to the left of each line (under the line number).
Code climate via Travis
If your project is public and open source, then there's an online option availble: set up Travis
for running your tests (it will pull your code on every Github commit) and also set up
Code Climate to assess the quality metrics of your code for free. The codeclimate-test-reporter
gem will send the results of your test run to Code Climate, which will then show a nice
badge which you can embed anywhere you think is a good idea (Github readme?) so that pepople
can see how good your coverage is and know how awesome you are.
Warning: coverage percentages may not be what they seem to be
Your integration tests may be exercising lots of code pathways, making the coverage tool think that it's all being tested, but when we examine what the test is really asserting, there is no check to see if the expected action has actually occurred. For this reason, code coverage tools should be used with caution: If they say you have no coverage, then you definitely don't, and you know what to fix first. However, if they say you do have coverage and you are not familiar with the test suite, then be careful - you may not be as safe as you think!
For example, the tests could be exercising lots of code paths and only checking one result e.g. that the page returns a 200 response code. In this case, all of the code to generate all of the page elements and to carry out all of the work in that controller action will look like it is covered. In reality, almost anything could be happening (or not) and you have no idea if it's broken.
Here's an example
for the clear action from the original tests for the resque-scheduler-web Sinatra code:
context 'on POST to /delayed/clear' do
setup { post '/delayed/clear' }
test 'redirects to delayed' do
assert last_response.status == 302
assert last_response.header['Location'].include? '/delayed'
end
end
Hmmm. There are no other unit tests covering this code at all, so it's a good thing I checked!
I later found out that this action is supposed to delete all of the currently scheduled delayed jobs. Not much in the test to indicate or assert this, though. This highlights how useful a comprehensive test suite would have been for onboarding new developers. It's not just about catching bugs!
Step 2: Read all of the existing tests
Seriously. All of them.
You may be lucky and inherit code with partial or even pretty good test coverage, but this doesn't mean you're OK to just trust them. The first thing to do is read them all so that you know what's there. There's just no way to know what you're dealing with otherwise, as we'll see.
To avoid the false impression of having thorough test coverage when you don't (as above), read and run each group of tests separately, with the coverage checker turned on. That way you can see exactly what's going on.
For unit tests, this means running the tests in one file, then going to the class it's testing and making a note of what is covered and what is not. However, this can still be misleading. Just because the code gets run once, does not mean that it is properly tested. You may need to test the code in more than one scenario. For example, if a method returns a boolean, then you need to test both a condition when it should be true and a condition when it should be false. Without this, a simple breakage that makes it return the same value all the time may not trigger any test failures. It's tempting to think that this would show up as a non-covered line in the coverage checker output for the method, but what if it looks like this?
def does_it_work?
@some_var == 'some_value'
end
This tests the truthiness of a statement on a single line, so it looks covered even with just one test. But what if you mistype the comparison operator like this:
def does_it_work?
@some_var = 'some_value'
end
This will always return true. If your single test only checks for a true outcome, you're in trouble. This shows that there is really no substitute for reading the test suite carefully as you work through it to see what's covered and what's not.
Integration tests require a different approach, as they exercise a lot of code without necessarily noting when the wrong thing happens, as we saw above. Here, your aim is to see how much of the user's happy path through the system is covered, so you can work out if more tests are required in order to catch regressions in future.
Take note: the ideal test suite for legacy code is not the same as when writing new code
OK, so now you should have a pretty good idea of what you've got to work with. If it turns out you have solid test coverage and need do no more, then congratulations! You're luckier than a lot of us :) However if you feel things could be be better, then you now need to work out what tests to add in order to be able to start maintaining or adding new features to the code. When I first started out, I thought that this would mean that I would need to try to get the test coverage to 100% so it would look the same as if I'd used behaviour driven development (BDD) from the start. Turns out, it's not that easy. With BDD, you start with the behaviour-specifying integration test (usually in Cucumber or one of its variants), then drop down into unit tests to make the components for your feature. This leads to both the happy path (and any important failure modes) being covered by Cucumber scenarios, as well as (theoretically) 100% unit test coverage. This is a great thing to aim for, but it can be very hard (or sometimes impossible) to retrofit onto existing code. There are several reasons for this.
1. What is the code even supposed to do??
One reason is that writing tests assumes that you know what the code is supposed to do in the first place. This is not always clear. Unless you have the original developer available to ask, you may unwittingly write tests which make assertions about the existing behaviour of code which has been broken for a while, without anyone one realising or fixing it. Just because it's there in the codebase does not mean it's necessarily bug-free. This is especially the case if it's untested, but test suites can sometimes be broken too. In this case, you would end up with a passing test suite for something that doesn't do what it's supposed to, masking the problem for the future.
This problem is often
relatively easy to get around with user scenarios/integration tests - just work through the same sequence
of actions in the browser and see if what happens makes sense. However, with unit tests it can be
extremely difficult to work out what the expected failure modes of any code are intended to be. Testing
that it works when following the happy path is sometimes all you can do. For example, this method in
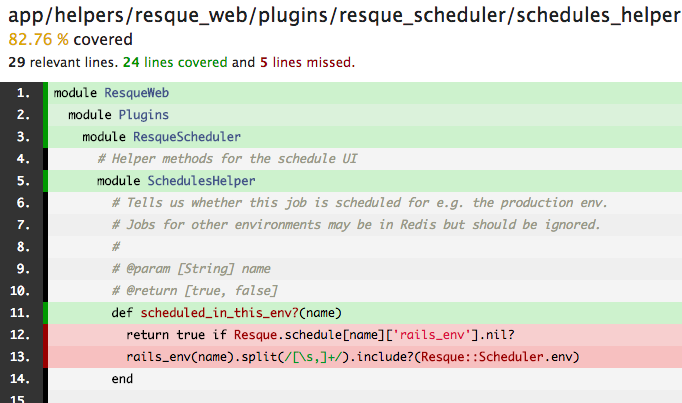
schedules_helper.rb in
in resque-scheduler-web (which outputs text for the UI based on the job's execution schedule) gives
us no indication of when 'Not currently scheduled' might be appropriate to display.
This line is currently not covered by any unit or integration tests, but what should a test that
covers this line look like? Without knowing how a job that is not scheduled could show up in the
scheduler interface, we are lost.
def schedule_interval(config)
if config['every']
schedule_interval_every(config['every'])
elsif config['cron']
'cron: ' + config['cron'].to_s
else
'Not currently scheduled'
end
end
2. Maybe you just can't test it?
A further problem arises when the code in question has simply not have been written with testing in mind. For example, it may be hard to unit test a class in isolation if it has loads of dependencies or is poorly structured. Alternatively, you may have code that only works in conjunction with an outside system, or which requires a very complex environment to be set up. In the end, it might be that the only way to add tests is to refactor the code drastically, which has a big risk of introducing new bugs. Not a good thing to be doing if you are already unsure what the code really does and have no test coverage in the first place.
3. Do you have the time?
Writing the tests for new code using the TDD/BDD approach means you are only writing the code you need, and you know exactly what it does, so you can work pretty quickly like this. However, if you reverse the process to retrofit the tests to existing code, it takes far longer. You have to factor in the time required to work out what the code is doing, work out how it might go wrong, refactor so that the code is easier to test, etc. This is a much slower process and you simply may not have the time to go through line by line and do this for the whole codebase or even part of it.
All of this together means that we can't really expect to get the same level of coverage when adding tests to legacy code as we would have had if we'd followed the BDD route from the start. So what's the minimum we should we aim for? Well, this will clearly vary a lot from project to project depending on the circumstances, so a fair bit of judgement (or finger-in-the-air guesswork) is required, but there are a few good starting points. What follows is my personal rule of thumb for working out what tests you need:
Step 3: Add characterisation tests that cover all of the users' happy path
Michael Feathers introduced the term Characterisation tests to describe integration tests which aimed to characterise the behaviour of code as it stands, rather than to drive new feature development or provide documentation of the intended business case (as BDD does). The primary aim is to prevent regressions when you make changes to legacy code. In my view, this is the first thing you should do once you've assessed the state of the existing test suite. You don't necessarily know what the reasoning is behind a certain design decision, but you can certainly write an integration test that asserts the existing behaviour continues to be there. If you feel any are missing, now's the time to add them.
You can write integration tests with Cucumber, or you can stick with the same framework you are using for unit testing. Which is best? For resque-scheduler-web, Cucumber seemed a bit like overkill, as the key benefit it offers over Rspec is that the tests are readable by non-technical people. Not likely to matter much for a gem that's mostly only of interest to back-end developers, but your situation may be different. Choose cucumber if you envisage having conversations with non-technical people about the system's current or future behaviour. Stick to your favourite unit testing framework if not.
Another consideration with integration tests is that they run slowly compared to unit tests,
so it's worth thinking about whether you really need slower browser-driven tests or not. For resque-scheduler-web,
I switched the test suite to use Rspec and Capybara, and for the most part stuck with the
default :rack_test driver, which just parses the
generated HTML. There's no JavaScript in the UI for this project, so this was fine as only the HTML needed to be verified.
After adding/refactoring test to cover the whole of the happy path, I had 55 integration
scenarios to cover all of the actions in two controllers (and a few important failure modes). The test suite now
runs in just over 4 seconds on a high-end MacBook Pro. This is fine, and is unlikely change as the functionality
in the gem is pretty much complete and won't grow too much. However,
if you have a complex bit of code, you may find that your characterisation tests take quite some time to run either now or in the future.
For this reason, consider tagging them in some way so you can skip them and only run the faster unit tests whilst
developing new code. This is not necessary if using Cucumber of course, but with Rspec, you would need something like this:
it "a test tagged with the 'integration' tag", integration: true do
# Test code...
end
Which allows you to skip the integration tests and run only the unit tests while you're coding, like this:
# On the command line in the root of the project
rspec . --integration ~skip
Or to run only the integration tests:
# On the command line in the root of the project
rspec . --integration
What about unit tests?
Characterisation tests both verify and document the behaviour of the system as you found it, so these are the tests you need as a minimum in order to be confident refactoring and adding new features. Given that all the user functionality should then be covered by them, unit tests to cover the same code are desirable, but likely not essential at this point. Another consideration is that any code which is lacking unit tests, but isn't going to change in the near future is unlikely to have new bugs introduced to it by changes to unrelated parts of the system. My approach is therefore to stop here and not try to add more unit tests for the sake of it. You just don't need them yet and the time trade off is often too much.
One exception I make is for unit tests that did not make much sense to you when I read over them in the previous steps. If they are hard to understand, then they may need to be simplified or refactored in order to help future developers (which usually means yourself in a few months time) to get up to speed quickly.
The future: Adding more tests during new development work
Later on, as you develop new features, you will (should) naturally be using the BDD cycle to drive your development, leaving lovely 100% covered code in your wake. However, you will also find yourself in a position where some refactoring of the legacy code is necessary at times. I think this is the point where unit tests are worth adding to the parts you are refactoring which lack them. Now that the legacy classes are being altered, there is a high chance of bugs being introduced during that process, so having fast unit tests to cover all possible regressions is worth the tradeoff.
